Run Machine Learning Inference on the NPU with PyTorch and ONNX#
Goals#
Introduce the Ryzen™ AI Software Platform
Show the ONNX model generation and inference flow on the NPU
Deploy a quantized ResNet-50 model onto Ryzen AI NPU for inference
References#
This is not currently supported on the Linux release of Riallto.
Ryzen AI Software Platform#
The AMD Ryzen™ AI Software Platform enables developers to take machine learning models trained in PyTorch or TensorFlow and run them on laptops powered by Ryzen AI. The Ryzen AI software platform intelligently optimizes tasks and workloads, freeing-up CPU and GPU resources, and ensuring optimal performance at lower power. The diagram below shows the flow from trained models to execution.

Step 1: Import Packages#
Run the following cell to import all the necessary packages to be able to run the inference in the Ryzen AI NPU.
import onnx
import onnxruntime as ort
import enum
import numpy as np
import cv2
import pickle
import os
import glob
import tarfile
import urllib.request
import matplotlib.pyplot as plt
from PIL import Image
from mpl_toolkits.axes_grid1 import ImageGrid
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sn
import pandas as pd
Step 2: Prepare the Data#
We are going to use a pre-trained ResNet-50 model from PyTorch Hub for the CIFAR-10 dataset.
Download the CIFAR-10 dataset#
Execute the following cells to download the CIFAR-10 dataset. The dataset is stored in data/cifar-10-batches-py/.
global models_dir, data_dir
models_dir = ".\\onnx"
data_dir= ".\\onnx\\data"
# License 1 (see end of notebook)
# Download data - One-time only
datadirname = ".\\onnx\\data"
if not os.path.exists(datadirname):
data_download_tar = "cifar-10-python.tar.gz"
urllib.request.urlretrieve("https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz", data_download_tar)
file = tarfile.open(data_download_tar)
file.extractall(data_dir)
file.close()
# Delete cifar-10-python.tar.gz source file after all images are extracted
data_images_path = os.path.join(os.getcwd(), "cifar-10-python.tar.gz")
files = glob.glob(data_images_path)
for f in files:
os.remove(f)
The CIFAR-10 dataset has 60,000 32x32 pixels color images in 10 classes, each class consists of 6,000 images.
There are 50,000 training images and 10,000 test images.
The dataset contains five training batches and one test batch, 10,000 images in each. Each class in the test batch has 1,000 randomly selected images.
The CIFAR10 classes are enumerated in the Cifar10Classes class below:
class Cifar10Classes(enum.Enum):
airplane = 0
automobile = 1
bird = 2
cat = 3
deer = 4
dog = 5
frog = 6
horse = 7
ship = 8
truck = 9
Run the following two cells to display a subset of the test images.
# License 2 (see end of notebook)
def unpickle(file):
with open(file,'rb') as fo:
dict = pickle.load(fo, encoding='latin1')
return dict
datafile = r'./onnx/data/cifar-10-batches-py/test_batch'
metafile = r'./onnx/data/cifar-10-batches-py/batches.meta'
test_batch = unpickle(datafile)
metadata = unpickle(metafile)
images = test_batch['data']
labels = test_batch['labels']
images = np.reshape(images,(10000, 3, 32, 32))
im = []
dirname = 'onnx/onnx_test_images'
if not os.path.exists(dirname):
os.mkdir(dirname)
for i in range(20):
im.append(cv2.cvtColor(images[i].transpose(1,2,0), cv2.COLOR_RGB2BGR))
fig = plt.figure(figsize=(10, 10))
grid = ImageGrid(fig, 111, # similar to subplot(111)
nrows_ncols=(4, 5), # creates 4x5 grid of axes
axes_pad=0.3, # pad between axes in inch.
)
for ax, image, label in zip(grid, im, labels):
ax.axis("off")
ax.imshow(image)
ax.set_title(f'Actual label: {Cifar10Classes(label).name}', fontdict={'fontsize':8})
plt.show()

Step 3: Deploy the Model on the NPU#
Run the next cell to set up the XLNX_VART_FIRMWARE environmental variable to point to the NPU binary. The NPU binary 1x4.xclbin is an AI design that provides up to 2 TOPS performance. Up to four such AI streams can be run in parallel on the NPU without any visible loss of performance.
# 1x4 array
os.environ['XLNX_VART_FIRMWARE'] = os.path.join("onnx", "xclbins","1x4.xclbin")
Load quantized ONNX model#
Run the following cell to load the provided ONNX quantized model.
We will use the following pre-trained quantized file:
The trained quantized ResNet-50 model on the CIFAR-10 dataset is saved at the following location:
onnx/resnet.qdq.U8S8.onnx
If you would like to re-train and quantize your model, please review the PyTorch ONNX re-train notebook.
# License 2 (see end of notebook)
quantized_model_path = r'./onnx/resnet.qdq.U8S8.onnx'
model = onnx.load(quantized_model_path)
Deploy the quantized ONNX model on the Ryzen AI NPU#
For more information on provider options visit ONNX Runtime with Vitis AI Execution Provider
The file onnx/vaip_config.json is required when configuring Vitis AI Execution Provider (VAI EP) inside the ONNX Runtime code.
# License 2 (see end of notebook)
providers = ['VitisAIExecutionProvider']
cache_dir = os.path.join(os.getcwd(), "onnx")
provider_options = [{
'config_file': 'onnx/xclbins/vaip_config.json',
'cacheDir': str(cache_dir),
'cacheKey': 'modelcachekey'
}]
session = ort.InferenceSession(model.SerializeToString(), providers=providers,
provider_options=provider_options)
Inference#
The first 20 images are extracted from the CIFAR-10 test dataset and converted to the .png format.
The .png images are read, classified and visualized by running the quantized ResNet-50 model on the NPU.
# License 2 (see end of notebook)
# Extract and dump first 20 images
for i in range(20):
im = images[i]
im = im.transpose(1,2,0)
im = cv2.cvtColor(im,cv2.COLOR_RGB2BGR)
im_name = f'./{dirname}/image_{i}.png'
cv2.imwrite(im_name, im)
viz_predicted_labels = []
misclassified_images = []
misclassified_labels = []
show_imlist = []
# Pick dumped images and predict
for i in range(20):
image_name = f'./{dirname}/image_{i}.png'
image = Image.open(image_name).convert('RGB')
# Resize the image to match the input size expected by the model
image = image.resize((32, 32))
image_array = np.array(image).astype(np.float32)
image_array = image_array/255
# Reshape the array to match the input shape expected by the model
image_array = np.transpose(image_array, (2, 0, 1))
# Add a batch dimension to the input image
input_data = np.expand_dims(image_array, axis=0)
# Run the model
outputs = session.run(None, {'input': input_data})
# Process the outputs
predicted_class = np.argmax(outputs[0])
predicted_label = metadata['label_names'][predicted_class]
viz_predicted_labels.append(predicted_class)
label = metadata['label_names'][labels[i]]
# print(f'Image {i}: Actual Label {label}, Predicted Label {predicted_label}')
if (label != predicted_label):
misclassified_images.append(i)
misclassified_labels.append(predicted_label)
show_imlist.append(cv2.cvtColor(images[i].transpose(1,2,0), cv2.COLOR_RGB2BGR))
fig = plt.figure(figsize=(10, 10))
grid = ImageGrid(fig, 111, # similar to subplot(111)
nrows_ncols=(4, 5), # creates 4x5 grid of axes
axes_pad=0.3, # pad between axes in inch.
)
for ax, image, label in zip(grid, show_imlist, viz_predicted_labels):
ax.axis("off")
ax.imshow(image)
ax.set_title(f'Predicted label: {Cifar10Classes(label).name}', fontdict={'fontsize':8})
plt.show()

Display the misclassifications
show_imlist_mis = []
for i in misclassified_images:
show_imlist_mis.append(cv2.cvtColor(images[i].transpose(1,2,0), cv2.COLOR_RGB2BGR))
varpltsize = len(misclassified_images)
fig = plt.figure(figsize=((1 * 2 * varpltsize), 1 * 2 * varpltsize))
grid = ImageGrid(fig, 111, # similar to subplot(111)
nrows_ncols=(1, len(misclassified_images)),
axes_pad=0.3, # pad between axes in inch.
)
for ax, image, label in zip(grid, show_imlist_mis, misclassified_labels):
ax.axis("off")
ax.imshow(image)
ax.set_title(f'Predicted label: {label}', fontdict={'fontsize':8})
plt.show()

Inference for more test images#
The first 5,000 images are extracted from the CIFAR-10 test dataset and converted to the .png format.
The .png images are read, classified and visualized by running the quantized ResNet-50 model on the NPU.
# License 2 (see end of notebook)
max_images = len(images)//2 # 5000 test images
# Extract and dump all images in the test set
for i in range(max_images):
im = images[i]
im = im.transpose(1,2,0)
im = cv2.cvtColor(im,cv2.COLOR_RGB2BGR)
im_name = f'./{dirname}/image_{i}.png'
cv2.imwrite(im_name, im)
cm_predicted_labels = []
cm_actual_labels = []
# Pick dumped images and predict
for i in range(max_images):
image_name = f'./{dirname}/image_{i}.png'
try:
image = Image.open(image_name).convert('RGB')
except:
print(f"Warning: Image {image_name} maybe locked moving on to next image")
continue
# Resize the image to match the input size expected by the model
image = image.resize((32, 32))
image_array = np.array(image).astype(np.float32)
image_array = image_array/255
# Reshape the array to match the input shape expected by the model
image_array = np.transpose(image_array, (2, 0, 1))
# Add a batch dimension to the input image
input_data = np.expand_dims(image_array, axis=0)
# Run the model
outputs = session.run(None, {'input': input_data})
# Process the outputs
predicted_class = np.argmax(outputs[0])
predicted_label = metadata['label_names'][predicted_class]
cm_predicted_labels.append(predicted_class)
label = metadata['label_names'][labels[i]]
cm_actual_labels.append(labels[i])
if i%990 == 0:
print(f'Status: Running Inference on image {i}... Actual Label: {label}, Predicted Label: {predicted_label}')
Status: Running Inference on image 0... Actual Label: cat, Predicted Label: cat
Status: Running Inference on image 990... Actual Label: automobile, Predicted Label: automobile
Status: Running Inference on image 1980... Actual Label: truck, Predicted Label: truck
Status: Running Inference on image 2970... Actual Label: dog, Predicted Label: dog
Status: Running Inference on image 3960... Actual Label: bird, Predicted Label: bird
Status: Running Inference on image 4950... Actual Label: bird, Predicted Label: bird
Confusion matrix#
The X-axis represents the predicted class and the Y-axis represents the actual class.
The diagonal cells show true positives, they show how many instances of each class were correctly predicted by the model. The off-diagonal cells show instances where the predicted class did not match the actual class.
cf_matrix = confusion_matrix(cm_actual_labels, cm_predicted_labels)
df = pd.DataFrame(cf_matrix/np.sum(cf_matrix,axis=1), index = [Cifar10Classes(i).name for i in range(10)], columns=[Cifar10Classes(i).name for i in range(10)])
plt.figure(figsize = (10,5));
sn.heatmap(df, annot=True, cmap="PiYG");
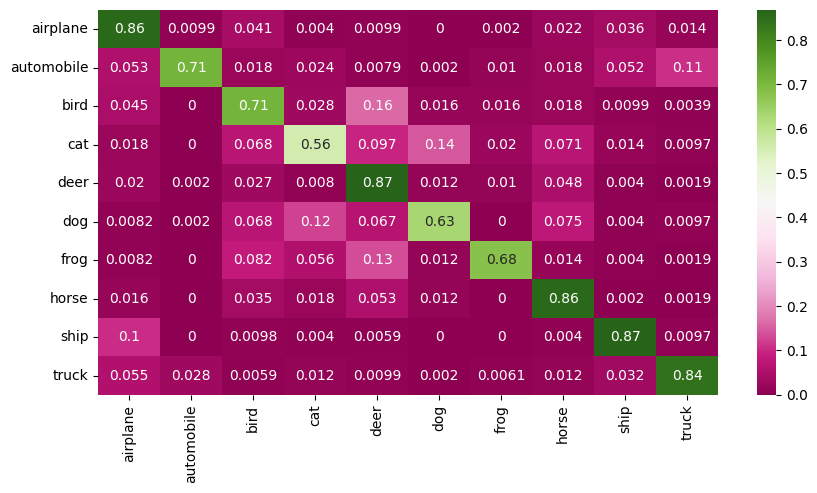
Accuracy of the quantized model for 5,000 test images#
print(f" Accuracy of the quantized model for the test set is : {(accuracy_score(cm_actual_labels, cm_predicted_labels)*100):.2f} %")
Accuracy of the quantized model for the test set is : 75.76 %
Step 4: Deploy the Model on CPU#
Deploy the Quantized ONNX Model on CPU (default provider)
providers = ['CPUExecutionProvider']
provider_options = [{}]
session = ort.InferenceSession(model.SerializeToString(), providers=providers,
provider_options=provider_options)
# License 2 (see end of notebook)
#Pick dumped images and predict
for i in range(10):
image_name = f'./{dirname}/image_{i}.png'
image = Image.open(image_name).convert('RGB')
# Resize the image to match the input size expected by the model
image = image.resize((32, 32))
image_array = np.array(image).astype(np.float32)
image_array = image_array/255
# Reshape the array to match the input shape expected by the model
image_array = np.transpose(image_array, (2, 0, 1))
# Add a batch dimension to the input image
input_data = np.expand_dims(image_array, axis=0)
# Run the model
outputs = session.run(None, {'input': input_data})
# Process the outputs
predicted_class = np.argmax(outputs[0])
predicted_label = metadata['label_names'][predicted_class]
label = metadata['label_names'][labels[i]]
print(f'Image {i}: Actual Label {label}, Predicted Label: {predicted_label}')
Image 0: Actual Label cat, Predicted Label: cat
Image 1: Actual Label ship, Predicted Label: ship
Image 2: Actual Label ship, Predicted Label: ship
Image 3: Actual Label airplane, Predicted Label: airplane
Image 4: Actual Label frog, Predicted Label: frog
Image 5: Actual Label frog, Predicted Label: frog
Image 6: Actual Label automobile, Predicted Label: automobile
Image 7: Actual Label frog, Predicted Label: frog
Image 8: Actual Label cat, Predicted Label: cat
Image 9: Actual Label automobile, Predicted Label: automobile
Delete all Extracted Images#
# Delete all extracted images to save disk space
images_path = os.path.join(os.getcwd(), "onnx", "onnx_test_images","*")
files = glob.glob(images_path)
for f in files:
try:
os.remove(f)
except:
continue
Licenses#
License 1
# -------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
# --------------------------------------------------------------------------
License 2
#################################################################################
# License
# Ryzen AI is licensed under `MIT License <https://github.com/amd/ryzen-ai-documentation/blob/main/License>`_ . Refer to the `LICENSE File <https://github.com/amd/ryzen-ai-documentation/blob/main/License>`_ for the full license text and copyright notice.